You're Billed for One Model. The Token Math Points to Another.
LLM model substitution and billing drift leave arithmetic traces in your own call log. model_receipt_probe.py reconciles requested model, response model, usage, and billed amount against one declared price policy, offline. In this post’s fixtures, one changed billed_usd field flips the verdict from 4 OK, exit 0, to BILLING_DRIFT with reconciles_with=haiku-4, exit 1.
AI disclosure: I wrote
model_receipt_probe.pywith an AI assistant and ran it myself, offline, before publishing. Every number in the output blocks below is pasted from a real local run on Python 3.13.5, standard library only, no network. I checked the exit codes (0 / 1 / 2), hashed the full STDOUT of every fixture twice to confirm it is byte-for-byte deterministic, and edited every line. The external figures I cite (the CISPA test in Kaspersky’s write-up, the arXiv substitution audit) are their numbers, not mine; I link the primary sources and keep their numbers out of my results.
In short:
- Between you and the model there now often stands a middleman: a gateway, a router, a relay. Whatever arrives in the response’s
modelfield is whatever that middleman chose to write there. - Your log already holds a receipt. Requested model, response model, token usage, billed amount: four fields, reconcilable offline against one declared price policy. No keys, no traffic.
- The demo that matters: two logs, byte-identical except one
billed_usdvalue. The model name saysopus-4in both. In one of them the charge only reconciles withhaiku-4rates. Exit 0 becomes exit 1, and the probe printsreconciles_with=haiku-4. - “No receipt” is a status, not an OK. A response with no usable model or usage fields is WARN, and FAIL under
--strict. - This catches the sloppy substitution and the drifted ledger, not the careful forgery. Absence of flags is not proof of authenticity, and I will say that again before the end.
The middleman moved in, and the receipt moved out
On June 30, Daniel Nwaneri published a Dev.to post about the gray market in resold AI access, and buried in it is the cleanest statement of this problem I have read: “you pay for opus, you get haiku, sometimes you get glm. you can’t verify which model answered you.” His words. The post ranges much wider, into claims I have not verified and will not repeat, but those two lines stand on their own. In the comments, a reader writing as kenielzep97 pushed it one turn further: “That’s not just theft, it’s an integrity break your logs say one thing ran and something else did, and no receipt survives the proxy.”
No receipt survives the proxy. I keep turning that phrase over, because it is half right, and the wrong half is the useful half. The proxy hands you no receipt. It also cannot stop you from rebuilding one, because four receipt fields are already sitting in your own call log, written by your own client at request time.
And the middle layer is not fringe anymore. This week’s Launch HN for an MCP cloud, Manufact, YC S25, sat at 104 points and 62 comments; gateways, routers, and relays now stand between a growing share of production calls and whatever model actually answers them. Some are excellent. All of them share one property: the model string in the response is theirs to write. A gateway without a receipt is trust dressed up as infrastructure.
So here is the thesis, stated so you can break it: given a call log and a declared price policy, every record’s verdict is computable offline, deterministically. The requested model and the response model must agree after an alias map. The billed amount must match usage times the declared model’s rates, within a declared tolerance. Show me a record where the arithmetic reconciles and the probe flags drift, or one where it does not and the probe stays quiet, and the tool is broken and this post with it.
What does a model receipt look like in your log?
Four fields per call: the model you asked for, the model the response claims, the token usage, the amount you were charged. A JSONL log that keeps them looks like this, one call per line:
{"id": "call-001", "requested_model": "opus-4", "base_url": "https://api.example-provider.com/v1/messages", "response": {"model": "opus-4", "usage": {"input_tokens": 12000, "output_tokens": 3000}}, "billed_usd": 0.405}
{"id": "call-002", "requested_model": "opus-4", "base_url": "https://api.example-provider.com/v1/messages", "response": {"model": "opus-4-20260115", "usage": {"input_tokens": 52000, "output_tokens": 8200}}, "billed_usd": 1.401}
{"id": "call-003", "requested_model": "sonnet-4", "base_url": "https://api.example-provider.com/v1/messages", "response": {"model": "sonnet-4", "usage": {"input_tokens": 230000, "output_tokens": 41000}}, "billed_usd": 1.305}
{"id": "call-004", "requested_model": "haiku-4", "base_url": "https://api.example-provider.com/v1/messages", "response": {"model": "haiku-4-20260110", "usage": {"input_tokens": 8000, "output_tokens": 1500}}, "billed_usd": 0.0155}The other input is a price policy you declare. One JSON file, local, never fetched:
{
"prices_per_mtok": {
"opus-4": {"in": 15.0, "out": 75.0},
"sonnet-4": {"in": 3.0, "out": 15.0},
"haiku-4": {"in": 1.0, "out": 5.0}
},
"aliases": {
"opus-4-20260115": "opus-4",
"sonnet-4-20260210": "sonnet-4",
"haiku-4-20260110": "haiku-4"
},
"official_hosts": ["api.example-provider.com"],
"tolerance_pct": 5
}Three things about this file, because each was a decision. The rates are fixture rates: plausible per-mtok numbers for a three-tier lineup, not any vendor’s live price list, and the model names are fixture context too, borrowed from the quote above. The aliases map is load-bearing: providers legitimately return dated snapshot names, and a probe that flags opus-4-20260115 against a requested opus-4 would drown you in false alarms by lunchtime. And tolerance_pct is required, not defaulted. My first draft defaulted it to 5 and I took that out: how much billing slack you accept is a policy decision, and a tool that quietly makes policy for you is how drift becomes normal.
Run it in sixty seconds
No keys. No network. No install beyond Python. The whole tool, one file, standard library only:
#!/usr/bin/env python3
"""
model_receipt_probe.py -- an offline receipt reconciler for LLM API calls,
run AFTER the responses land, against the log you already keep.
Every LLM call leaves four receipt fields in a well-kept log: the model you
requested, the model the response claims, the token usage, and the amount
you were billed. This probe reconciles all four against ONE declared price
policy, record by record, and names the disagreement:
RECEIPT_MISMATCH FAIL canon(response.model) != canon(requested_model)
after the alias map (so a legitimate dated
snapshot name is NOT flagged)
BILLING_DRIFT FAIL |billed_usd - usage x price(requested model)|
beyond tolerance_pct; the probe then reprices
the same usage under every other model in the
policy and prints reconciles_with=<model> when
the charge matches a different one
NO_RECEIPT WARN the response carries no usable model and/or
usage ("no receipt" is a status, not an OK);
FAIL under --strict
UNPRICED_MODEL WARN the requested model is not in the price table
(the probe says "cannot reconcile", it does
not guess)
ENDPOINT_NON_OFFICIAL INFO host(base_url) is not in official_hosts
Inputs:
argv[1] JSONL log, one call per line:
{"id": ..., "requested_model": ..., "base_url": ...,
"response": {"model": ..., "usage": {"input_tokens": N,
"output_tokens": N}}, "billed_usd": X}
argv[2] price policy JSON (a LOCAL file you declare, not a network fetch):
{"prices_per_mtok": {...}, "aliases": {...},
"official_hosts": [...], "tolerance_pct": N}
argv[3] optional --strict: WARN escalates to FAIL
Exit codes (usable as a CI gate):
0 no FAIL (WARNs allowed without --strict)
1 >=1 FAIL, or >=1 WARN under --strict
2 bad input (missing args, unreadable file, malformed JSON or JSONL
line, missing required field, negative or non-numeric tokens or
billed_usd) -- the probe fails closed
Offline. Keyless. Read-only. Zero network. Standard library only (json,
sys). It reconciles the log you kept against the policy you declared. If
the log lies about usage or the charge, the probe will not know. A pass
is "the receipt is arithmetically consistent", never "the right model
answered".
Usage:
python3 model_receipt_probe.py <calls.jsonl> <price_policy.json> [--strict]
"""
import json
import sys
def _bad(msg):
print("ERROR: " + msg)
raise SystemExit(2)
def _num(value):
return isinstance(value, (int, float)) and not isinstance(value, bool)
def _host(url):
rest = url.split("://", 1)[-1]
host = rest.split("/", 1)[0]
host = host.rsplit("@", 1)[-1]
return host.split(":", 1)[0].lower()
def _usd(value):
return "%.6f" % value
def _pct(value):
# round first, then add 0.0 so a float-noise -0.0 prints as +0.0
return "%+.1f%%" % (round(value, 1) + 0.0)
def load_policy(path):
try:
with open(path, "r") as fh:
raw = fh.read()
except OSError as exc:
_bad("cannot read price policy: %s" % exc)
try:
data = json.loads(raw)
except json.JSONDecodeError as exc:
_bad("price policy is not valid JSON: %s" % exc)
if not isinstance(data, dict):
_bad("price policy must be a JSON object")
prices = data.get("prices_per_mtok")
if not isinstance(prices, dict) or not prices:
_bad("policy.prices_per_mtok must be a non-empty object")
for name in sorted(prices):
row = prices[name]
if not isinstance(row, dict):
_bad("prices_per_mtok[%s] must be an object" % name)
for side in ("in", "out"):
if not _num(row.get(side)) or row[side] < 0:
_bad("prices_per_mtok[%s].%s must be a number >= 0"
% (name, side))
aliases = data.get("aliases", {})
if not isinstance(aliases, dict):
_bad("policy.aliases must be an object")
for key in sorted(aliases):
if not isinstance(aliases[key], str):
_bad("aliases[%s] must map to a model name string" % key)
hosts = data.get("official_hosts", [])
if not isinstance(hosts, list) or not all(
isinstance(h, str) for h in hosts):
_bad("policy.official_hosts must be a list of host strings")
tol = data.get("tolerance_pct")
if not _num(tol) or tol < 0:
_bad("policy.tolerance_pct must be a number >= 0 (declare it; "
"the probe does not assume a tolerance)")
return prices, aliases, [h.lower() for h in hosts], float(tol)
def load_records(path):
try:
with open(path, "r") as fh:
lines = fh.read().splitlines()
except OSError as exc:
_bad("cannot read call log: %s" % exc)
records = []
for n, line in enumerate(lines, 1):
if not line.strip():
continue
try:
rec = json.loads(line)
except json.JSONDecodeError as exc:
_bad("line %d is not valid JSON: %s" % (n, exc))
if not isinstance(rec, dict):
_bad("line %d must be a JSON object" % n)
records.append((n, rec))
if not records:
_bad("call log contains no records")
return records
def validate_record(n, rec):
for key in ("id", "requested_model"):
if not isinstance(rec.get(key), str) or not rec[key]:
_bad("line %d: '%s' must be a non-empty string" % (n, key))
if not _num(rec.get("billed_usd")) or rec["billed_usd"] < 0:
_bad("line %d: 'billed_usd' must be a number >= 0" % n)
if "base_url" in rec and not isinstance(rec["base_url"], str):
_bad("line %d: 'base_url' must be a string" % n)
resp = rec.get("response")
if resp is not None and not isinstance(resp, dict):
_bad("line %d: 'response' must be an object" % n)
if isinstance(resp, dict):
if "model" in resp and not isinstance(resp["model"], str):
_bad("line %d: 'response.model' must be a string" % n)
usage = resp.get("usage")
if usage is not None:
if not isinstance(usage, dict):
_bad("line %d: 'response.usage' must be an object" % n)
for side in ("input_tokens", "output_tokens"):
tok = usage.get(side)
if not isinstance(tok, int) or isinstance(tok, bool) \
or tok < 0:
_bad("line %d: 'response.usage.%s' must be an "
"integer >= 0" % (n, side))
def expected_usd(usage, row):
return (usage["input_tokens"] / 1e6 * row["in"]
+ usage["output_tokens"] / 1e6 * row["out"])
def within(billed, expected, tol):
if expected == 0:
return billed == 0
return abs(billed - expected) <= tol / 100.0 * expected
def evaluate(rec, prices, aliases, hosts, tol):
"""Returns (status, detail_lines, tag) for one validated record."""
canon = lambda name: aliases.get(name, name)
requested = rec["requested_model"]
canon_req = canon(requested)
billed = rec["billed_usd"]
resp = rec.get("response") or {}
resp_model = resp.get("model")
usage = resp.get("usage")
fails, warns, infos, lines = [], [], [], []
missing = [name for name, val in
(("model", resp_model), ("usage", usage)) if val is None]
if missing:
warns.append("NO_RECEIPT")
lines.append("NO_RECEIPT: response carries no %s; "
"billed_usd=%s cannot be fully reconciled"
% (" or ".join(missing), _usd(billed)))
if resp_model is not None and canon(resp_model) != canon_req:
fails.append("RECEIPT_MISMATCH")
lines.append("RECEIPT_MISMATCH: requested %s, response says %s"
% (canon_req, canon(resp_model)))
reconciles = []
if usage is not None:
if canon_req not in prices:
warns.append("UNPRICED_MODEL")
lines.append("UNPRICED_MODEL: '%s' not in price policy; "
"cannot reconcile billed_usd=%s"
% (canon_req, _usd(billed)))
else:
expected = expected_usd(usage, prices[canon_req])
delta = ((billed - expected) / expected * 100.0
if expected else 0.0)
base = ("usage=%din/%dout expected_usd=%s billed_usd=%s "
"delta=%s"
% (usage["input_tokens"], usage["output_tokens"],
_usd(expected), _usd(billed), _pct(delta)))
if within(billed, expected, tol):
lines.append(base)
else:
fails.append("BILLING_DRIFT")
lines.append("BILLING_DRIFT: %s tolerance=%.1f%%"
% (base, tol))
for name in sorted(prices):
if name == canon_req:
continue
other = expected_usd(usage, prices[name])
if within(billed, other, tol):
reconciles.append((name, other))
if reconciles:
for name, other in reconciles:
d = ((billed - other) / other * 100.0
if other else 0.0)
lines.append("reconciles_with=%s expected_usd=%s "
"delta=%s" % (name, _usd(other),
_pct(d)))
lines.append("the receipt names %s; the arithmetic "
"prices %s"
% (canon_req,
",".join(n for n, _ in reconciles)))
else:
lines.append("reconciles_with=none of the %d priced "
"models" % len(prices))
if hosts and isinstance(rec.get("base_url"), str):
host = _host(rec["base_url"])
if host not in hosts:
infos.append("ENDPOINT_NON_OFFICIAL")
lines.append("ENDPOINT_NON_OFFICIAL: host %s not in "
"official_hosts (info, not proof)" % host)
if fails:
status = "FAIL"
elif warns:
status = "WARN"
elif infos:
status = "INFO"
else:
status = "OK"
tag = ",".join(fails + warns + infos) if status != "OK" else "OK"
shown = resp_model if resp_model is not None else "(absent)"
if resp_model is not None and canon(resp_model) != resp_model:
shown = "%s (canon %s)" % (resp_model, canon(resp_model))
head = ("- %s requested=%s response=%s -> %s"
% (rec["id"], requested, shown,
tag if status != "OK" else "OK"))
return status, head, lines, fails + warns
def main(argv):
args = [a for a in argv[1:] if a != "--strict"]
strict = "--strict" in argv[1:]
if len(args) != 2:
print("usage: model_receipt_probe.py <calls.jsonl> "
"<price_policy.json> [--strict]")
raise SystemExit(2)
prices, aliases, hosts, tol = load_policy(args[1])
records = load_records(args[0])
for n, rec in records:
validate_record(n, rec)
out = []
out.append("MODEL-RECEIPT-PROBE REPORT")
out.append("price policy: %d models priced, %d aliases, "
"tolerance %.1f%%, official hosts: %d"
% (len(prices), len(aliases), tol, len(hosts)))
out.append("mode: %s" % ("strict (WARN fails)"
if strict else "default (WARN reported)"))
out.append("records: %d" % len(records))
counts = {"OK": 0, "FAIL": 0, "WARN": 0, "INFO": 0}
flagged = []
for _, rec in records:
status, head, lines, reasons = evaluate(rec, prices, aliases,
hosts, tol)
counts[status] += 1
out.append(" " + head)
for line in lines:
out.append(" " + line)
if status == "FAIL" or (strict and status == "WARN"):
flagged.append((rec["id"], ",".join(reasons)))
out.append("receipts: %d OK, %d FAIL, %d WARN, %d INFO"
% (counts["OK"], counts["FAIL"], counts["WARN"],
counts["INFO"]))
if flagged:
out.append("flagged records:")
for rid, reasons in flagged:
out.append(" - %s: %s" % (rid, reasons))
out.append("VERDICT: FAIL: %d of %d receipts do not reconcile "
"with the declared price policy%s"
% (len(flagged), len(records),
" (strict: WARN escalated)" if strict
and counts["WARN"] else ""))
code = 1
else:
note = (" (%d WARN reported, not escalated; --strict escalates)"
% counts["WARN"]) if counts["WARN"] else ""
out.append("VERDICT: PASS: no receipt fails reconciliation "
"against the declared price policy%s" % note)
code = 0
print("\n".join(out))
raise SystemExit(code)
if __name__ == "__main__":
main(sys.argv)The baseline: four receipts, four reconciliations
$ python3 model_receipt_probe.py fixtures/clean.jsonl fixtures/prices.json
MODEL-RECEIPT-PROBE REPORT
price policy: 3 models priced, 3 aliases, tolerance 5.0%, official hosts: 1
mode: default (WARN reported)
records: 4
- call-001 requested=opus-4 response=opus-4 -> OK
usage=12000in/3000out expected_usd=0.405000 billed_usd=0.405000 delta=+0.0%
- call-002 requested=opus-4 response=opus-4-20260115 (canon opus-4) -> OK
usage=52000in/8200out expected_usd=1.395000 billed_usd=1.401000 delta=+0.4%
- call-003 requested=sonnet-4 response=sonnet-4 -> OK
usage=230000in/41000out expected_usd=1.305000 billed_usd=1.305000 delta=+0.0%
- call-004 requested=haiku-4 response=haiku-4-20260110 (canon haiku-4) -> OK
usage=8000in/1500out expected_usd=0.015500 billed_usd=0.015500 delta=+0.0%
receipts: 4 OK, 0 FAIL, 0 WARN, 0 INFO
VERDICT: PASS: no receipt fails reconciliation against the declared price policyExit 0. Worth pausing on call-002: the response says opus-4-20260115, the request said opus-4, and the alias map canonicalizes both to the same name, so no flag. Its charge runs 0.4 percent over the computed expectation, inside the 5 percent tolerance; metering slack and rounding live in that gap. Notice also that the probe prints its arithmetic for clean records too. A reconciliation you cannot see is a reconciliation you cannot argue with.
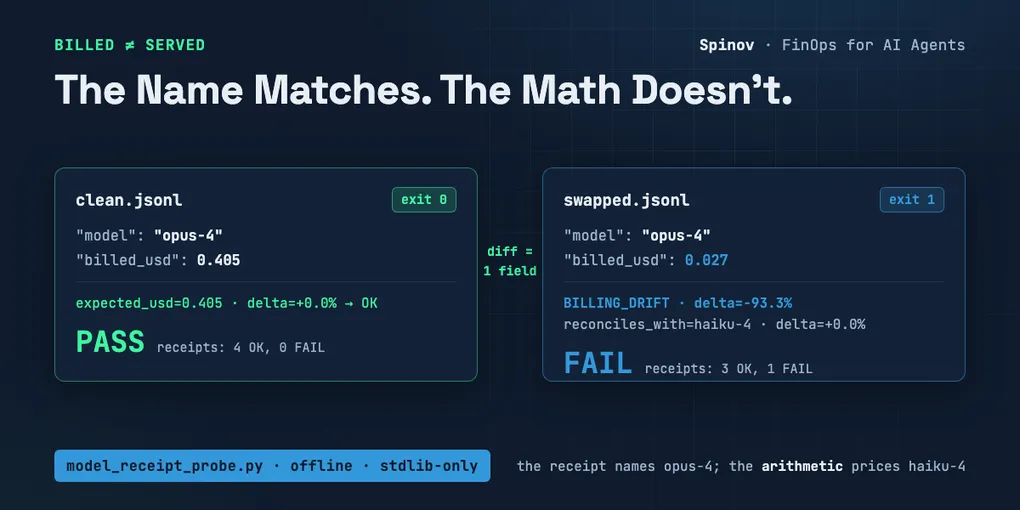
One billing field flips the verdict
Now the demo this post exists for. The second log is byte-identical to the first except one field on one line:
$ diff fixtures/clean.jsonl fixtures/swapped.jsonl
1c1
< {"id": "call-001", "requested_model": "opus-4", "base_url": "https://api.example-provider.com/v1/messages", "response": {"model": "opus-4", "usage": {"input_tokens": 12000, "output_tokens": 3000}}, "billed_usd": 0.405}
---
> {"id": "call-001", "requested_model": "opus-4", "base_url": "https://api.example-provider.com/v1/messages", "response": {"model": "opus-4", "usage": {"input_tokens": 12000, "output_tokens": 3000}}, "billed_usd": 0.027}The model name still says opus-4. The usage is untouched. Only the charge moved.
$ python3 model_receipt_probe.py fixtures/swapped.jsonl fixtures/prices.json
MODEL-RECEIPT-PROBE REPORT
price policy: 3 models priced, 3 aliases, tolerance 5.0%, official hosts: 1
mode: default (WARN reported)
records: 4
- call-001 requested=opus-4 response=opus-4 -> BILLING_DRIFT
BILLING_DRIFT: usage=12000in/3000out expected_usd=0.405000 billed_usd=0.027000 delta=-93.3% tolerance=5.0%
reconciles_with=haiku-4 expected_usd=0.027000 delta=+0.0%
the receipt names opus-4; the arithmetic prices haiku-4
- call-002 requested=opus-4 response=opus-4-20260115 (canon opus-4) -> OK
usage=52000in/8200out expected_usd=1.395000 billed_usd=1.401000 delta=+0.4%
- call-003 requested=sonnet-4 response=sonnet-4 -> OK
usage=230000in/41000out expected_usd=1.305000 billed_usd=1.305000 delta=+0.0%
- call-004 requested=haiku-4 response=haiku-4-20260110 (canon haiku-4) -> OK
usage=8000in/1500out expected_usd=0.015500 billed_usd=0.015500 delta=+0.0%
receipts: 3 OK, 1 FAIL, 0 WARN, 0 INFO
flagged records:
- call-001: BILLING_DRIFT
VERDICT: FAIL: 1 of 4 receipts do not reconcile with the declared price policyExit 1, and the drift line does the naming. Billed 0.027 against an expected 0.405 is 93.3 percent light, far outside tolerance; the probe then reprices the same usage under every other model in the table, and exactly one reconciles. The receipt names opus-4. The arithmetic prices haiku-4.
Why would a swap ever leave this trace? Because the laziest version of the swap is a pass-through: route the call to the cheap model, forward the upstream meter, forge the name, ship it. The name is one string. The charge carries the cheap model’s entire rate structure, input and output rates both, and repricing it to match the story takes work. The economics of this business select for people who skip work. The same economics cut the other way, though: stripping usage out of the response is even less work than forwarding it, and that shows up here as NO_RECEIPT rather than drift, which is one more reason --strict is the CI mode.
And the money frame, since this blog is about the bill. At this fixture’s rates the identical usage costs 0.405 under opus-4 arithmetic and 0.027 under haiku-4 arithmetic, a 15x spread on a single call. Fixture units, not a prod measurement, so resist multiplying it by your monthly call volume; the point survives without the multiplication. Whoever controls the routing chooses which of those two numbers you pay, and this probe at least tells you which one your ledger recorded. If your agent spends its own budget autonomously, the same reconciliation is just spend integrity wearing different table names.
When the name check and the money check agree
The edge fixture holds the blunter case, plus one deliberate footnote:
{"id": "call-101", "requested_model": "opus-4", "base_url": "https://api.example-provider.com/v1/messages", "response": {"model": "haiku-4", "usage": {"input_tokens": 40000, "output_tokens": 9000}}, "billed_usd": 0.085}
{"id": "call-102", "requested_model": "haiku-4", "base_url": "https://llm-relay.example-cheap.io/v1/messages", "response": {"model": "haiku-4", "usage": {"input_tokens": 8000, "output_tokens": 1500}}, "billed_usd": 0.0155}$ python3 model_receipt_probe.py fixtures/edge.jsonl fixtures/prices.json
MODEL-RECEIPT-PROBE REPORT
price policy: 3 models priced, 3 aliases, tolerance 5.0%, official hosts: 1
mode: default (WARN reported)
records: 2
- call-101 requested=opus-4 response=haiku-4 -> RECEIPT_MISMATCH,BILLING_DRIFT
RECEIPT_MISMATCH: requested opus-4, response says haiku-4
BILLING_DRIFT: usage=40000in/9000out expected_usd=1.275000 billed_usd=0.085000 delta=-93.3% tolerance=5.0%
reconciles_with=haiku-4 expected_usd=0.085000 delta=+0.0%
the receipt names opus-4; the arithmetic prices haiku-4
- call-102 requested=haiku-4 response=haiku-4 -> ENDPOINT_NON_OFFICIAL
usage=8000in/1500out expected_usd=0.015500 billed_usd=0.015500 delta=+0.0%
ENDPOINT_NON_OFFICIAL: host llm-relay.example-cheap.io not in official_hosts (info, not proof)
receipts: 0 OK, 1 FAIL, 0 WARN, 1 INFO
flagged records:
- call-101: RECEIPT_MISMATCH,BILLING_DRIFT
VERDICT: FAIL: 1 of 2 receipts do not reconcile with the declared price policycall-101 is the middleman who did not even forge the name: requested opus-4, response says haiku-4, and the charge reconciles with haiku-4 rates. Two independent checks, one story. When the name check and the money check accuse the same model, your ticket to the supplier writes itself.
call-102 is INFO by design. A base_url off the official host list is a fact worth logging and a poor thing to fail on, since relays and regional endpoints can be entirely legitimate; I already spent a whole post on identity checks before anything runs, in the pre-install supply-chain gate, and I am not rebuilding it here as a side effect. One line of code, one line of prose, moving on.
Why is “no receipt” a warning and not an OK?
$ python3 model_receipt_probe.py fixtures/no_receipt.jsonl fixtures/prices.json
MODEL-RECEIPT-PROBE REPORT
price policy: 3 models priced, 3 aliases, tolerance 5.0%, official hosts: 1
mode: default (WARN reported)
records: 3
- call-201 requested=opus-4 response=opus-4 -> NO_RECEIPT
NO_RECEIPT: response carries no usage; billed_usd=0.405000 cannot be fully reconciled
- call-202 requested=glm-5-air response=glm-5-air -> UNPRICED_MODEL
UNPRICED_MODEL: 'glm-5-air' not in price policy; cannot reconcile billed_usd=0.021000
- call-203 requested=opus-4 response=(absent) -> NO_RECEIPT
NO_RECEIPT: response carries no model or usage; billed_usd=0.405000 cannot be fully reconciled
receipts: 0 OK, 0 FAIL, 3 WARN, 0 INFO
VERDICT: PASS: no receipt fails reconciliation against the declared price policy (3 WARN reported, not escalated; --strict escalates)call-201 has a model and no usage. call-203 has no response fields at all. call-202 asked for glm-5-air, and sometimes you do get glm; there is no such row in my price table, so the probe prints UNPRICED_MODEL and refuses to guess. All three are WARN: reported, unescalated, exit 0. Pass --strict and the same log fails:
$ python3 model_receipt_probe.py fixtures/no_receipt.jsonl fixtures/prices.json --strict
MODEL-RECEIPT-PROBE REPORT
price policy: 3 models priced, 3 aliases, tolerance 5.0%, official hosts: 1
mode: strict (WARN fails)
records: 3
- call-201 requested=opus-4 response=opus-4 -> NO_RECEIPT
NO_RECEIPT: response carries no usage; billed_usd=0.405000 cannot be fully reconciled
- call-202 requested=glm-5-air response=glm-5-air -> UNPRICED_MODEL
UNPRICED_MODEL: 'glm-5-air' not in price policy; cannot reconcile billed_usd=0.021000
- call-203 requested=opus-4 response=(absent) -> NO_RECEIPT
NO_RECEIPT: response carries no model or usage; billed_usd=0.405000 cannot be fully reconciled
receipts: 0 OK, 0 FAIL, 3 WARN, 0 INFO
flagged records:
- call-201: NO_RECEIPT
- call-202: UNPRICED_MODEL
- call-203: NO_RECEIPT
VERDICT: FAIL: 3 of 3 receipts do not reconcile with the declared price policy (strict: WARN escalated)That escalation exists because “cannot reconcile” quietly becoming “fine” is exactly how a year of unauditable spend accumulates. Which brings me to a live example, offered without blame. On June 27, a Dev.to author writing as Lolo shipped an AI API gateway, a genuinely useful wrapper-killer, and the comment thread went straight at this post’s subject. A reader, Kartik N V J K, asked: “Are you planning to expose token usage and latency per request, or keep the surface purely credit-based?” The author’s answer, honest and typical of the whole category: “Currently credit-based only, but exposing raw tokens + latency per request is on the roadmap…” Run the mapping: a credit-based surface with no per-request usage means every call through it lands as NO_RECEIPT under this probe. Not fraudulent. Unauditable. If you operate a gateway, exposing the four fields lets your users run this exact check against you, and “auditable” is a feature you can put on the pricing page.
Their numbers, not mine: what LLM model substitution costs when it happens
Three external data points, clearly attributed, none of them mine.
Kaspersky’s July 1 write-up by Stan Kaminsky on LLM aggregator and AI API proxy risk cites a test by researchers at the CISPA Helmholtz Center: sending a complex medical query directly to Gemini 2.5 yielded over 83 percent accuracy, while routing the same query through rogue proxies dropped it to 37 percent. Their test, their numbers. My probe sees none of that quality collapse; it sees the money end only. The two failure surfaces travel together, which is what makes the cheap offline check worth running at all.
On the theory side, Cai, Shi, Zhao, and Song audited model substitution in LLM APIs directly in arXiv 2504.04715, and their conclusions set this post’s ceiling: statistical tests on text outputs are “query-intensive and fail” against subtle substitution, log-probability methods are “defeated by inherent inference nondeterminism”, and the fix they propose is trusted execution environments at the hardware layer. Their conclusion, not mine, and it is why this probe attempts no output fingerprinting at all. Bookkeeping reconciliation is a weaker claim than a proof of model identity. It is also free, retrospective, and runs on logs you already have.
Practitioners have meanwhile converged on the online version of this check: the awesome-ai-api-proxy repo calls a small set of reproducible canary prompts, re-run weekly against both the official API and the relay, the single most effective defense against a relay quietly substituting a cheaper model. That is an active method: you send traffic, you pay for it, you compare live. I built one of those once, a transaction canary, and the two classes complement rather than compete: canaries sample the present, receipts audit the past. The same repo also cites a relay-endpoint study with striking substitution percentages; it names no primary source I could chase down, so those numbers stay out of this post.
Where this sits in the series
This is a spoke on the pre-execution gate for AI agents cluster, and the first one aimed squarely at the supplier side of the trust boundary.
- Reconciling a scorecard from evidence is the closest cousin and the sharpest contrast: there I reconcile my own agent’s aggregate scorecard against my own evidence log. Our numbers, our lie. Today’s probe points the same reflex outward, at the per-call receipt a supplier hands back: different actor, different boundary, record-by-record grain.
- Your agent returns 200 and lies is the agent lying about its own work. Here the agent may be perfectly honest; what is in question is the middleman’s account of whose work you were billed for.
- Yesterday’s taint lint asked who writes the signals a gate reads before it authorizes anything, and the trace-versus-policy gate before it verdicts on actions an agent took. Both face inward and run around execution time. This probe reads the far end of the pipe: after the response, who answered, and at what rate.
- The router credential post lives on the same boundary as this one, with a different threat: there your secret leaks through the middle layer; here the middle layer edits who it says did the work.
What this is NOT
I would rather undersell this than have you deploy it as something it is not.
- Not a cryptographic proof of substitution. A careful middleman forges the model field and reprices the charge to match; the arithmetic then reconciles and the probe passes. Absence of flags is never proof of authenticity. What it catches is the sloppy swap and the drifted ledger. My prior says sloppiness is common in this economy, but that is a prior, not a census.
- Not a network audit and not canary prompting. Nothing is sent, nothing is measured online. If you need the active version, the canary approach above is the right class of tool.
- Not an accusation of any provider. The fixtures are synthetic and the model names are fixture context from a quote. A flag means “open a ticket with your supplier and verify”, not a fraud verdict. There are boring explanations for drift, starting with a stale price table.
- Two rates per model is the whole price model. Cache reads and writes, batch discounts, long-context tiers: real 2026 bills carry structure this probe does not price, so on a log full of cached or batched calls it will flag honest records, and a
reconciles_withline on such a record is noise, not evidence. The tolerance is also relative with no absolute floor, so a ledger rounded to whole cents false-flags calls whose true price is a fraction of a cent. Extend the model or filter those records before trusting a flag. - The probe trusts the policy file you hand it. An alias pointing at a name missing from the price table quietly downgrades the headline double-FAIL to an UNPRICED_MODEL warning, and default mode exits 0 on warnings;
--strictcloses that. It is also per-record only: a middleman skimming consistently just under your tolerance stays green, and catching that means summing the printed deltas over a period, which the output already lets you do. - The bundled price policy ages, and so does the alias map. Vendors change rates; a stale price table produces false drift. Vendors also ship new dated snapshot names: hand this policy a response naming
opus-4-20270101and it comes back RECEIPT_MISMATCH even though nothing was swapped, because the alias map has never heard of it. Tolerance absorbs metering slack, not policy rot. Treat the policy file like a lockfile: declared, versioned, updated on purpose. - Garbage in, garbage out. The probe reconciles the log you kept. If the middleman also writes your log, or the
usageandbilled_usdfields are themselves fabricated, the arithmetic will agree with the fabrication. Receipts you did not write yourself are testimony, not evidence. The same goes for abilled_usdyou backfilled as usage times price: then the drift check reconciles your multiplication against your multiplication, and a pass is circular. That field has to come from the charge side, an invoice line, a credits ledger, a gateway cost field. - Fixture units, not a prod measurement. The 4 OK, the 1 of 4, the 15x spread: all describe this post’s synthetic logs. Run it on your own history to get numbers that mean something about your stack.
Bad input fails closed
A probe that shrugs at a malformed ledger is worse than no probe:
$ python3 model_receipt_probe.py fixtures/bad.jsonl fixtures/prices.json
ERROR: line 2 is not valid JSON: Expecting property name enclosed in double quotes: line 1 column 173 (char 172)
$ echo $?
2Missing arguments, unreadable files, a policy without tolerance_pct, negative or non-numeric token counts, a record without billed_usd: all exit 2, distinct from exit 1, so your CI can tell “the ledger drifted” apart from “I could not read the ledger”. I ran every fixture twice and hashed the full STDOUT both times: clean is 908287d1..., swapped is 83e864ed..., edge is 0fe9c60c..., no-receipt is 2b695548... and its strict pass 32b4fe22..., identical across runs, Python 3.13.5, offline. One confession from the first draft: call-003 printed delta=-0.0%, float noise from summing 0.69 and 0.615. Deterministic, technically correct, unreadable. The percent formatter now rounds before it prints, and that was the only line the demo made me change.
The question I actually want answered
Open your LLM call log, today’s slice, and check whether it retains all four receipt fields: the model you requested, the model the response claimed, the usage, and the amount you were actually charged for that call. My guess is the fourth one is missing in most stacks, because the charge lives in a monthly invoice three systems away from the log, and per-call cost gets reconstructed, if ever, in a spreadsheet at month’s end. I would put money on fewer than half of production stacks being able to join all four for an arbitrary call, but that is a prior, not a measurement. Which field is missing in yours, and what would it take to join it? If you can produce even one day’s worth, run the probe and tell me which reason code fires first. My bet is NO_RECEIPT long before any drift.
If this was useful, follow along here for the next runnable gate in the series, and drop the worst billing surprise a middle layer ever handed you in the comments. I read every comment.